
Let´s say that you have a list of clients which you would like to insert into your database. If you don´t have access to an ETL Tool (such as Oracle Data Integrator, IBM DataStage, Microsoft Integration Services…) maybe it could look like a problem, but it’s not.
You can use the BULK INSERT command to perform this task. It´s not difficult, you just need to follow a few steps:
Consider that you have a list of clients as shown in the picture below:
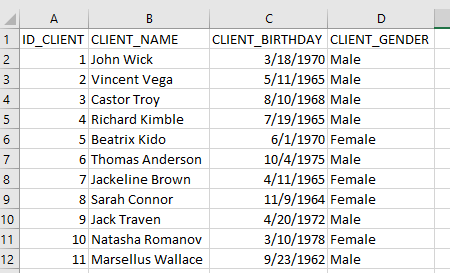
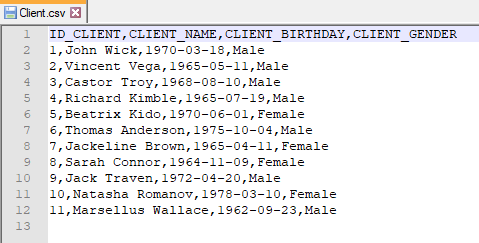
Our purpose now is to insert the information of this file into a database table, so the first step is to save this file as csv (comma separated value).
Temporary table and Target Table
In order to extract data, first we have to define the structure that will receive the data. For that reason we will create two tables:
1) One temporary table with all columns defined as varchar. This table it`s only to move the data from file to the table. Once we have the data transferred to the table we can do transformation and adjustments, when it’s required.
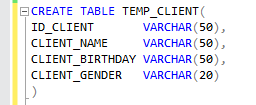
2) One target table which will receive the final version of the data with their datatypes.

Now that we defined the structures to receive data, we will finally work on the extraction.
BULK INSERT command
BULK INSERT
{ database_name.schema_name.table_or_view_name | schema_name.table_or_view_name | table_or_view_name }
FROM 'data_file'
[ WITH
(
[ [ , ] BATCHSIZE = batch_size ]
[ [ , ] CHECK_CONSTRAINTS ]
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ [ , ] DATAFILETYPE =
{ 'char' | 'native'| 'widechar' | 'widenative' } ]
[ [ , ] DATA_SOURCE = 'data_source_name' ]
[ [ , ] ERRORFILE = 'file_name' ]
[ [ , ] ERRORFILE_DATA_SOURCE = 'data_source_name' ]
[ [ , ] FIRSTROW = first_row ]
[ [ , ] FIRE_TRIGGERS ]
[ [ , ] FORMATFILE_DATA_SOURCE = 'data_source_name' ]
[ [ , ] KEEPIDENTITY ]
[ [ , ] KEEPNULLS ]
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ]
[ [ , ] LASTROW = last_row ]
[ [ , ] MAXERRORS = max_errors ]
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,…n ] ) ]
[ [ , ] ROWS_PER_BATCH = rows_per_batch ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
[ [ , ] TABLOCK ]
-- input file format options
[ [ , ] FORMAT = 'CSV' ]
[ [ , ] FIELDQUOTE = 'quote_characters']
[ [ , ] FORMATFILE = 'format_file_path' ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
)]
Note that the words in bold represent the settings that define the peculiarities or behaviors expected from the extraction.
You can find more details about these settings on: BULK INSERT (Transact-SQL) – SQL Server | Microsoft Docs
For our example, we will only use the command below:
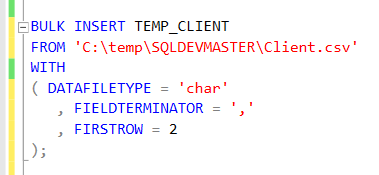
- BULK INSERT TEMP_CLIENT: all contents from file will be redirected to the table TEMP_CLIENT;
- FROM ‘C:\temp\SQLDEVMASTER\Client.csv’: the source of data is the file Client.csv, located on the path ‘C:\temp\SQLDEVMASTER’. (Remember considering your file system definitions when testing this);
- WITH: this defines the group of comands which will specify some characteristics from your file and the loading process;
- DATAFILETYPE = ‘char’: the file is character type.
- FIELDTERMINATOR: this is the most important detail, it defines where the column begins and finishes;
- FIRSTROW = 2: In the case your file has headers, you should inform that the load have to start from the second row.
Remember that you have to clean the TEMP table before executing the BULK INSERT.
After running the command we can see the data on the temp table:

Remember, that the temp table is a transport table. For the case we have already data loaded into this table, we don´t want the data to be removed. We want the existent data to be updated and the non-existent to be inserted. The date of insertion and update will be stored on LAST_UPDATE column.
UPDATE
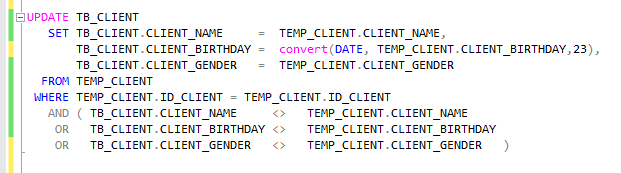
Note that on the update we are using the ID_CLIENT as key and we only update the row which at least one of the columns NAME, BIRTHDAY or GENDER is different.
INSERT

Note that, based on the ID_CLIENT as key, we insert only the rows that don´t exist in the target table.
Finally we have data available in the target table:

The script for this solution is in the link below:
The file CLIENT.csv is on the link below: